本节文章对刷天梯赛的过程作一些记录,主要是一些题目自己的理解。
涉及到一些数据,熟悉其基本原理,并加以例题帮助理解。
Nothing is unreachable ! to me
L1-064 估值一亿的AI核心代码 (20 分) 以上图片来自新浪微博。
本题要求你实现一个稍微更值钱一点的 AI 英文问答程序,规则是:
无论用户说什么,首先把对方说的话在一行中原样打印出来;
消除原文中多余空格:把相邻单词间的多个空格换成 1 个空格,把行首尾的空格全部删掉,把标点符号前面的空格删掉;
把原文中所有大写英文字母变成小写,除了 I;
把原文中所有独立的 can you、could you 对应地换成 I can、I could—— 这里“独立”是指被空格或标点符号分隔开的单词;
把原文中所有独立的 I 和 me 换成 you;
把原文中所有的问号 ? 换成惊叹号 !;
在一行中输出替换后的句子作为 AI 的回答。
输入格式:
输入首先在第一行给出不超过 10 的正整数 N,随后 N 行,每行给出一句不超过 1000 个字符的、以回车结尾的用户的对话,对话为非空字符串,仅包括字母、数字、空格、可见的半角标点符号。
输出格式:
按题面要求输出,每个 AI 的回答前要加上 AI: 和一个空格。
输入样例:
1 2 3 4 5 6 7 6 Hello ? Good to chat with you can you speak Chinese? Really? Could you show me 5 What Is this prime? I,don 't know
输出样例:
1 2 3 4 5 6 7 8 9 10 11 12 Hello ? AI: hello! Good to chat with you AI: good to chat with you can you speak Chinese? AI: I can speak chinese! Really? AI: really! Could you show me 5 AI: I could show you 5 What Is this prime? I,don 't know AI: what Is this prime! you,don't know
解法(STL字符串处理):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> #include <string> using namespace std ;int main () int N; string str; cin >> N; cin .get(); while (N-- > 0 ) { getline(cin , str); cout << str << endl ; str = ' ' + str + ' ' ; for (int i = 1 ; i < str.size(); i++) { if (str[i-1 ] == ' ' && !isalnum (str[i])) { str.erase(i-1 , 1 ); i--; } if (str[i] != 'I' && isupper (str[i])) str[i] = tolower (str[i]); if (str[i] == '?' ) str.replace(i, 1 , "!" ); } for (int i = 0 ; i < str.size(); i++) { if (str.substr(i, 7 ) == "can you" && !isalnum (str[i-1 ]) && !isalnum (str[i+7 ])) str.replace(i, 7 , "# can" ); if (str.substr(i, 9 ) == "could you" && !isalnum (str[i-1 ]) && !isalnum (str[i+9 ])) str.replace(i, 9 , "# could" ); if (str.substr(i, 1 ) == "I" && !isalnum (str[i-1 ]) && !isalnum (str[i+1 ])) str.replace(i, 1 , "you" ); if (str.substr(i, 2 ) == "me" && !isalnum (str[i-1 ]) && !isalnum (str[i+2 ])) str.replace(i, 2 , "you" ); } for (int i = 0 ; i < str.size(); i++) if (str[i] == '#' ) str[i] = 'I' ; while (str[0 ] == ' ' ) str.erase(0 ,1 ); while (str[str.size() - 1 ] == ' ' ) str.erase(str.size()-1 ,1 ); cout << "AI: " << str << endl ; } return 0 ; }
并查集
初始化结点
1 2 3 4 5 void init () for (int i = 1 ; i <= n; i++) father[i] = i; }
查找一个结点的根结点
1 2 3 4 5 6 int get (int x) if (father[x] == x) return x; return father[x] = get(father[x]); }
合并
1 2 3 4 5 6 7 void merge (int x, int y) x = get(x); y = get(y); if (x != y) father[y] = x; }
例题(luogu)
题目背景
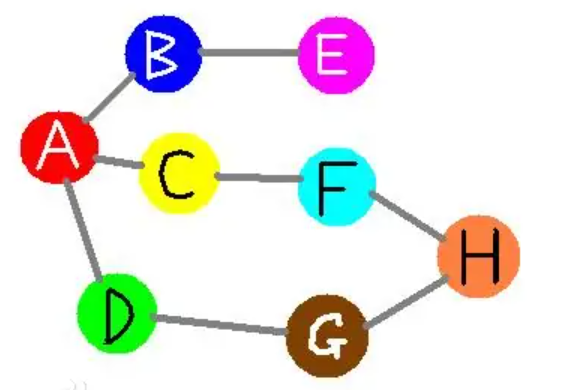
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。
题目描述
规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。
输入格式
第一行:三个整数n,m,p,(n<=5000,m<=5000,p<=5000),分别表示有n个人,m个亲戚关系,询问p对亲戚关系。
以下m行:每行两个数Mi,Mj,1<=Mi,Mj<=N,表示Mi和Mj具有亲戚关系。
接下来p行:每行两个数Pi,Pj,询问Pi和Pj是否具有亲戚关系。
输出格式
P行,每行一个’Yes’或’No’。表示第i个询问的答案为“具有”或“不具有”亲戚关系。
输入输出样例
1 2 3 4 5 6 7 8 9 6 5 3 1 2 1 5 3 4 5 2 1 3 1 4 2 3 5 6
solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std ;int n, m, p, a, b, c, d, father[5005 ];int get (int x) if (father[x] == x) return x; return father[x] = get(father[x]); } void merge (int x, int y) x = get(x); y = get(y); if (x != y) father[y] = x; } int main () cin >> n >> m >> p; for (int i = 1 ; i <= n; i++) father[i] = i; for (int i = 0 ; i < m; i++) { cin >> a >> b; merge(a, b); } while (p--) { cin >> c >> d; c = get(c); d = get(d); if (c == d) cout << "Yes" << endl ; else cout << "No" << endl ; } return 0 ; }
L1-002 打印沙漏 (20 分)
本题要求你写个程序把给定的符号打印成沙漏的形状。例如给定17个“*”,要求按下列格式打印
1 2 3 4 5 ***** *** * *** *****
所谓“沙漏形状”,是指每行输出奇数个符号;各行符号中心对齐;相邻两行符号数差2;符号数先从大到小顺序递减到1,再从小到大顺序递增;首尾符号数相等。
给定任意N个符号,不一定能正好组成一个沙漏。要求打印出的沙漏能用掉尽可能多的符号。
输入格式:
输入在一行给出1个正整数N(≤1000)和一个符号,中间以空格分隔。
输出格式:
首先打印出由给定符号组成的最大的沙漏形状,最后在一行中输出剩下没用掉的符号数。
输入样例:
输出样例:
1 2 3 4 5 6 ***** *** * *** ***** 2
分析
本道题为找规律题,前半段的行数与总数之间存在2*N^2-1的关系,发现这个关系后,就转化为普通的打印形状题
solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <cstdio> using namespace std ;int main () int N, row, remain; char ch; scanf ("%d %c" , &N, &ch); while (true ) { if (2 *row*row-1 > N) break ; else row++; } row--; remain = N - (2 *row*row-1 ); for (int i = row; i > 0 ; i--) { for (int k = 0 ; k < row - i; k++) printf (" " ); for (int j = 2 *i - 1 ; j > 0 ; j--) printf ("%c" , ch); printf ("\n" ); } for (int i = 2 ; i < row+1 ; i++) { for (int k = 0 ; k < row - i; k++) printf (" " ); for (int j = 2 *i - 1 ; j > 0 ; j--) printf ("%c" , ch); printf ("\n" ); } printf ("%d\n" , remain); return 0 ; }
L1-011 A-B (20 分)
本题要求你计算A −B 。不过麻烦的是,A 和B 都是字符串 —— 即从字符串A 中把字符串B 所包含的字符全删掉,剩下的字符组成的就是字符串A −B 。
输入格式:
输入在2行中先后给出字符串A 和B 。两字符串的长度都不超过104,并且保证每个字符串都是由可见的ASCII码和空白字符组成,最后以换行符结束。
输出格式:
在一行中打印出A −B 的结果字符串。
输入样例:
1 2 I love GPLT! It's a fun game! aeiou
输出样例:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> #include <string> using namespace std ;int main () string A, B; getline(cin , A); getline(cin , B); for (int i = 0 ; i < B.size(); i++) { for (int j = 0 ; j < A.size(); j++) { if (A[j] == B[i]) { A.replace(j, 1 , "" ); j--; } } } cout << A << endl ; return 0 ; }
L1-027 出租 (20 分) 输入格式:
输入在一行中给出一个由11位数字组成的手机号码。
输出格式:
为输入的号码生成代码的前两行,其中arr中的数字必须按递减顺序给出。
输入样例:
输出样例:
1 2 int[] arr = new int[]{8,3,2,1,0}; int[] index = new int[]{3,0,4,3,1,0,2,4,3,4,4};
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> #include <set> #include <algorithm> using namespace std ;class MyCompare { public : bool operator () (int a, int b) return a > b; } }; int main () string phonenum; cin >> phonenum; set <int ,MyCompare>s; for (int i = 0 ; i < 11 ; i++) s.insert(phonenum[i] - '0' ); cout << "int[] arr = new int[]{" ; for (set <int , MyCompare>::iterator it = s.begin(); it != s.end(); it++) { cout << *it; if (++it != s.end()) cout << "," ; it--; } cout << "};" << endl ; cout << "int[] index = new int[]{" ; for (int i = 0 ; i < 11 ; i++) { int j = 0 ; for (set <int , MyCompare>::iterator it = s.begin(); it != s.end(); it++) { if ((phonenum[i] - '0' ) == *it) { cout << j; if (i+1 != 11 ) cout << "," ; break ; } j++; } } cout << "};" << endl ; return 0 ; }
L1-032 Left-pad (20 分)
根据新浪微博上的消息,有一位开发者不满NPM(Node Package Manager)的做法,收回了自己的开源代码,其中包括一个叫left-pad的模块,就是这个模块把javascript里面的React/Babel干瘫痪了。这是个什么样的模块?就是在字符串前填充一些东西到一定的长度。例如用*去填充字符串GPLT,使之长度为10,调用left-pad的结果就应该是******GPLT。Node社区曾经对left-pad紧急发布了一个替代,被严重吐槽。下面就请你来实现一下这个模块。
输入格式:
输入在第一行给出一个正整数N(≤104)和一个字符,分别是填充结果字符串的长度和用于填充的字符,中间以1个空格分开。第二行给出原始的非空字符串,以回车结束。
输出格式:
在一行中输出结果字符串。
输入样例1:
输出样例1:
输入样例2:
1 2 4 * this is a sample for cut
输出样例2:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <stdio.h> #include <string> using namespace std ;int main () int N; string str, ch; cin >> N >> ch; cin .get(); getline(cin , str); int len = str.size(); if (len >= N) { string substr = str.substr(len-N, N); cout << substr << endl ; } else { int i = len; while (i < N) { str = ch + str; i++; } cout << str << endl ; } return 0 ; }
L1-039 古风排版 (20 分)
中国的古人写文字,是从右向左竖向排版的。本题就请你编写程序,把一段文字按古风排版。
输入格式:
输入在第一行给出一个正整数N (<100),是每一列的字符数。第二行给出一个长度不超过1000的非空字符串,以回车结束。
输出格式:
按古风格式排版给定的字符串,每列N 个字符(除了最后一列可能不足N 个)。
输入样例:
输出样例:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <string> using namespace std ;int main () int N; cin >> N; cin .get(); string str; getline(cin , str); while (str.size() % N != 0 ) str += " " ; for (int i = 0 ; i < N; i++) { int j = str.size() / N-1 ; while (j >= 0 ) { cout << str[i+j*N]; j--; } cout << endl ; } return 0 ; }
L1-056 猜数字 (20 分)
一群人坐在一起,每人猜一个 100 以内的数,谁的数字最接近大家平均数的一半就赢。本题就要求你找出其中的赢家。
输入格式:
输入在第一行给出一个正整数N(≤104)。随后 N 行,每行给出一个玩家的名字(由不超过8个英文字母组成的字符串)和其猜的正整数(≤ 100)。
输出格式:
在一行中顺序输出:大家平均数的一半(只输出整数部分)、赢家的名字,其间以空格分隔。题目保证赢家是唯一的。
输入样例:
1 2 3 4 5 6 7 8 7 Bob 35 Amy 28 James 98 Alice 11 Jack 45 Smith 33 Chris 62
输出样例:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <vector> #include <string> #include <cmath> using namespace std ;int main () int N; cin >> N; vector <int > vi; vector <string > vs; for (int i = 0 ; i < N; i++) { string name; cin >> name; vs.push_back(name); int num; cin >> num; vi.push_back(num); } int aver = 0 ; for (int i = 0 ; i < vi.size(); i++) aver += vi[i]; aver /= N; aver /= 2 ; int j = 0 ; int min = abs (vi[0 ] - aver); for (int i = 1 ; i < vi.size(); i++) { int temp = abs (vi[i] - aver); if (temp <= min) { j = i; min = temp; } } cout << aver << " " << vs[j] << endl ; return 0 ; }
L1-059 敲笨钟 (20 分)
微博上有个自称“大笨钟V”的家伙,每天敲钟催促码农们爱惜身体早点睡觉。为了增加敲钟的趣味性,还会糟改几句古诗词。其糟改的方法为:去网上搜寻压“ong”韵的古诗词,把句尾的三个字换成“敲笨钟”。例如唐代诗人李贺有名句曰:“寻章摘句老雕虫,晓月当帘挂玉弓”,其中“虫”(chong)和“弓”(gong)都压了“ong”韵。于是这句诗就被糟改为“寻章摘句老雕虫,晓月当帘敲笨钟”。
现在给你一大堆古诗词句,要求你写个程序自动将压“ong”韵的句子糟改成“敲笨钟”。
输入格式:
输入首先在第一行给出一个不超过 20 的正整数 N。随后 N 行,每行用汉语拼音给出一句古诗词,分上下两半句,用逗号 , 分隔,句号 . 结尾。相邻两字的拼音之间用一个空格分隔。题目保证每个字的拼音不超过 6 个字符,每行字符的总长度不超过 100,并且下半句诗至少有 3 个字。
输出格式:
对每一行诗句,判断其是否压“ong”韵。即上下两句末尾的字都是“ong”结尾。如果是压此韵的,就按题面方法糟改之后输出,输出格式同输入;否则输出 Skipped,即跳过此句。
输入样例:
1 2 3 4 5 6 5 xun zhang zhai ju lao diao chong, xiao yue dang lian gua yu gong. tian sheng wo cai bi you yong, qian jin san jin huan fu lai. xue zhui rou zhi leng wei rong, an xiao chen jing shu wei long. zuo ye xing chen zuo ye feng, hua lou xi pan gui tang dong. ren xian gui hua luo, ye jing chun shan kong.
输出样例:
1 2 3 4 5 xun zhang zhai ju lao diao chong, xiao yue dang lian qiao ben zhong. Skipped xue zhui rou zhi leng wei rong, an xiao chen jing qiao ben zhong. Skipped Skipped
解法一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <string> using namespace std ;int main () int N, len, pos; cin >> N; cin .get(); while (N-->0 ) { string str; getline(cin , str);· len = str.size(); pos = str.find("," ); if (pos >= 3 && str.substr(pos-3 , 3 ) == "ong" && str.substr(len-4 , 3 ) == "ong" ) { string substr = str; int pos2; for (int i = 0 ; i < 3 ; i++) { pos2 = substr.rfind(" " ); substr = str.substr(0 , pos2); } cout << str.substr(0 , pos2+1 ) << "qiao ben zhong." << endl ; } else cout << "Skipped" << endl ; } return 0 ; }
解法二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <string> using namespace std ;int main () int N; cin >> N; cin .get(); while (N-->0 ) { string str; getline(cin , str); if (str.find("ong," ) != str.npos && str.rfind("ong." ) != str.npos) { string substr = str; int pos; for (int i = 0 ; i < 3 ; i++) { pos = substr.rfind(" " ); substr = str.substr(0 , pos); } cout << str.substr(0 , pos+1 ) << "qiao ben zhong." << endl ; } else cout << "Skipped" << endl ; } return 0 ; }
L1-071 前世档案 (20 分) 输入格式:
输入第一行给出两个正整数:N (≤30)为玩家做一次测试要回答的问题数量;M (≤100)为玩家人数。
随后 M 行,每行顺次给出玩家的 N 个回答。这里用 y 代表“是”,用 n 代表“否”。
输出格式:
对每个玩家,在一行中输出其对应的结论的编号。
输入样例:
输出样例:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <stdio.h> #include <cmath> using namespace std ;int main () int N, M; scanf ("%d %d" , &N, &M); cin .get(); while (M-- > 0 ) { int score = 1 ; for (int i = 0 ; i < N; i++) { char ch = cin .get(); if (ch == 'n' ) score = score + pow (2 , N-i-1 ); } cout << score << endl ; cin .get(); } return 0 ; }
L2-010 排座位 (25 分)
布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位。无论如何,总不能把两个死对头排到同一张宴会桌旁!这个艰巨任务现在就交给你,对任何一对客人,请编写程序告诉主人他们是否能被安排同席。
输入格式:
输入第一行给出3个正整数:N(≤100),即前来参宴的宾客总人数,则这些人从1到N编号;M为已知两两宾客之间的关系数;K为查询的条数。随后M行,每行给出一对宾客之间的关系,格式为:宾客1 宾客2 关系,其中关系为1表示是朋友,-1表示是死对头。注意两个人不可能既是朋友又是敌人。最后K行,每行给出一对需要查询的宾客编号。
这里假设朋友的朋友也是朋友。但敌人的敌人并不一定就是朋友,朋友的敌人也不一定是敌人。只有单纯直接的敌对关系才是绝对不能同席的。
输出格式:
对每个查询输出一行结果:如果两位宾客之间是朋友,且没有敌对关系,则输出No problem;如果他们之间并不是朋友,但也不敌对,则输出OK;如果他们之间有敌对,然而也有共同的朋友,则输出OK but...;如果他们之间只有敌对关系,则输出No way。
输入样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 7 8 4 5 6 1 2 7 -1 1 3 1 3 4 1 6 7 -1 1 2 1 1 4 1 2 3 -1 3 4 5 7 2 3 7 2
输出样例:
1 2 3 4 No problem OK OK but... No way
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <cstdio> using namespace std ;int N, M, K, b1, b2, r;int father[105 ], enemy[105 ][105 ];int get (int x) if (father[x] == x) return x; return father[x] = get(father[x]); } void merge (int x, int y) x = get(x); y = get(y); if (x != y) { father[y] = x; } } int main () scanf ("%d %d %d" , &N, &M, &K); for (int i = 1 ; i <= N; i++) father[i] = i; for (int i = 0 ; i < M; i++) { scanf ("%d %d %d" , &b1, &b2, &r); if (r == 1 ) merge(b1, b2); else if (r == -1 ) enemy[b1][b2] = enemy[b2][b1] = 1 ; } while (K--) { scanf ("%d %d" , &b1, &b2); if (get(b1) == get(b2) && enemy[b1][b2] != 1 ) printf ("No problem\n" ); else if (get(b1) != get(b2) && enemy[b1][b2] != 1 ) printf ("OK\n" ); else if (get(b1) == get(b2) && enemy[b1][b2] == 1 ) printf ("OK but...\n" ); else printf ("No way\n" ); } return 0 ; }
L2-019 悄悄关注 (25 分)
新浪微博上有个“悄悄关注”,一个用户悄悄关注的人,不出现在这个用户的关注列表上,但系统会推送其悄悄关注的人发表的微博给该用户。现在我们来做一回网络侦探,根据某人的关注列表和其对其他用户的点赞情况,扒出有可能被其悄悄关注的人。
输入格式:
输入首先在第一行给出某用户的关注列表,格式如下:
其中N是不超过5000的正整数,每个用户i(i=1, …, N)是被其关注的用户的ID,是长度为4位的由数字和英文字母组成的字符串,各项间以空格分隔。
之后给出该用户点赞的信息:首先给出一个不超过10000的正整数M,随后M行,每行给出一个被其点赞的用户ID和对该用户的点赞次数(不超过1000),以空格分隔。注意:用户ID是一个用户的唯一身份标识。题目保证在关注列表中没有重复用户,在点赞信息中也没有重复用户。
输出格式:
我们认为被该用户点赞次数大于其点赞平均数、且不在其关注列表上的人,很可能是其悄悄关注的人。根据这个假设,请你按用户ID字母序的升序输出可能是其悄悄关注的人,每行1个ID。如果其实并没有这样的人,则输出“Bing Mei You”。
输入样例1:
1 2 3 4 5 6 7 8 9 10 10 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao 8 Magi 50 Pota 30 LLao 3 Ammy 48 Dave 15 GAO3 31 Zoro 1 Cath 60
输出样例1:
输入样例2:
1 2 3 4 5 6 7 8 9 11 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao Pota 7 Magi 50 Pota 30 LLao 48 Ammy 3 Dave 15 GAO3 31 Zoro 29
输出样例2:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std ;struct USER { string name; int good; }user[10005 ]; int main () set <string >s; set <string > s2; string str; bool flag = true ; int N, M, num, avg = 0 ; cin >> N; while (N--) { cin >> str; s.insert(str); } cin >> M; for (int i = 0 ; i < M; i++) { cin >> str >> num; user[i].name = str; user[i].good = num; avg += num; } avg /= M; for (int i = 0 ; i < M; i++) { if (user[i].good > avg && s.find(user[i].name) == s.end()) { s2.insert(user[i].name); flag = false ; } } if (flag) cout << "Bing Mei You" << endl ; else { for (auto it = s2.begin(); it != s2.end(); it++) cout << *it << endl ; } return 0 ; }
L2-033 简单计算器 (25 分) 本题要求你为初学数据结构的小伙伴设计一款简单的利用堆栈执行的计算器。如上图所示,计算器由两个堆栈组成,一个堆栈 S 1 存放数字,另一个堆栈 S 2 存放运算符。计算器的最下方有一个等号键,每次按下这个键,计算器就执行以下操作:
从 S 1 中弹出两个数字,顺序为 n 1 和 n 2;
从 S 2 中弹出一个运算符 op;
执行计算 n 2 op n 1;
将得到的结果压回 S 1。
直到两个堆栈都为空时,计算结束,最后的结果将显示在屏幕上。
输入格式:
输入首先在第一行给出正整数 N (1<N ≤103),为 S 1 中数字的个数。
第二行给出 N 个绝对值不超过 100 的整数;第三行给出 N −1 个运算符 —— 这里仅考虑 +、-、*、/ 这四种运算。一行中的数字和符号都以空格分隔。
输出格式:
将输入的数字和运算符按给定顺序分别压入堆栈 S 1 和 S 2,将执行计算的最后结果输出。注意所有的计算都只取结果的整数部分。题目保证计算的中间和最后结果的绝对值都不超过 109。
如果执行除法时出现分母为零的非法操作,则在一行中输出:ERROR: X/0,其中 X 是当时的分子。然后结束程序。
输入样例 1:
输出样例 1:
输入样例 2:
输出样例 2:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <stack> #include <vector> using namespace std ;int main () char ch; int N, num, a, b, result; cin >> N; stack <int > si; stack <char > sc; for (int i = 0 ; i < N; i++) { cin >> num; si.push(num); } for (int i = 0 ; i < N -1 ; i++) { cin >> ch; sc.push(ch); } while (!sc.empty()) { b = si.top(); si.pop(); a = si.top(); si.pop(); ch = sc.top(); sc.pop(); switch (ch) { case '+' : result = a + b; break ; case '-' : result = a - b; break ; case '*' : result = a * b; break ; case '/' : { if (b == 0 ) { printf ("ERROR: %d/0\n" , a); goto flag; } else result = a / b; break ; } } si.push(result); } cout << si.top() << endl ; flag: return 0 ; }
L2-031 深入虎穴 (25 分)
著名的王牌间谍 007 需要执行一次任务,获取敌方的机密情报。已知情报藏在一个地下迷宫里,迷宫只有一个入口,里面有很多条通路,每条路通向一扇门。每一扇门背后或者是一个房间,或者又有很多条路,同样是每条路通向一扇门…… 他的手里有一张表格,是其他间谍帮他收集到的情报,他们记下了每扇门的编号,以及这扇门背后的每一条通路所到达的门的编号。007 发现不存在两条路通向同一扇门。
内线告诉他,情报就藏在迷宫的最深处。但是这个迷宫太大了,他需要你的帮助 —— 请编程帮他找出距离入口最远的那扇门。
输入格式:
输入首先在一行中给出正整数 N (<105),是门的数量。最后 N 行,第 i 行(1≤i ≤N )按以下格式描述编号为 i 的那扇门背后能通向的门:
其中 K 是通道的数量,其后是每扇门的编号。
输出格式:
在一行中输出距离入口最远的那扇门的编号。题目保证这样的结果是唯一的。
输入样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 13 3 2 3 4 2 5 6 1 7 1 8 1 9 0 2 11 10 1 13 0 0 1 12 0 0
输出样例:
solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <bits/stdc++.h> using namespace std ;struct DOOR { int pos, dis; }; int main () int N, K, j, temp, longestdis = -1 ; cin >> N; int arr[N+1 ] = {0 }; vector <vector <int >> v (N+1 ) queue <DOOR> q; vector <DOOR> ans; for (int i = 1 ; i <= N; i++) { cin >> K; while (K--) { cin >> temp; v[i].push_back(temp); arr[temp] = 1 ; } } for (int i = 1 ; i <= N; i++) { if (arr[i] != 1 ) { j = i; break ; } } q.push({j, 0 }); while (!q.empty()) { DOOR d = q.front(); int pos = d.pos, dis = d.dis; if (dis > longestdis) longestdis = dis; ans.push_back(d); q.pop(); for (int i = 0 ; i < v[pos].size(); i++) q.push({v[pos][i], dis+1 }); } for (int i = 0 ; i < ans.size(); i++) { if (ans[i].dis == longestdis) { cout << ans[i].pos << endl ; break ; } } return 0 ; }
L3-003 社交集群 (30 分)
当你在社交网络平台注册时,一般总是被要求填写你的个人兴趣爱好,以便找到具有相同兴趣爱好的潜在的朋友。一个“社交集群”是指部分兴趣爱好相同的人的集合。你需要找出所有的社交集群。
输入格式:
输入在第一行给出一个正整数 N(≤1000),为社交网络平台注册的所有用户的人数。于是这些人从 1 到 N 编号。随后 N 行,每行按以下格式给出一个人的兴趣爱好列表:
K**i : h**i [1] h**i [2] … h**i [K**i ]
其中K**i (>0)是兴趣爱好的个数,h**i [j ]是第j 个兴趣爱好的编号,为区间 [1, 1000] 内的整数。
输出格式:
首先在一行中输出不同的社交集群的个数。随后第二行按非增序输出每个集群中的人数。数字间以一个空格分隔,行末不得有多余空格。
输入样例:
1 2 3 4 5 6 7 8 9 8 3: 2 7 10 1: 4 2: 5 3 1: 4 1: 3 1: 4 4: 6 8 1 5 1: 4
输出样例:
解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include <bits/stdc++.h> using namespace std ;int father[1005 ];struct NODE { int people; bool flag = false ; }ans[1005 ]; int get (int x) if (father[x] == x) return x; return father[x] = get(father[x]); } void merge (int x, int y) x = get(x); y = get(y); if (x != y) father[y] = x; } int cmp (NODE a, NODE b) return a.people > b.people; } int main () int N, K, h, h2, cnt = 0 ; vector <int >vi; for (int i = 1 ; i < 1005 ; i++) father[i] = i; scanf ("%d" , &N); for (int i = 0 ; i < N; i++) { scanf ("%d: %d" , &K, &h); vi.push_back(h); if (K == 1 ) { merge(h, h); continue ; } for (int j = 1 ; j < K; j++) { scanf ("%d" , &h2); merge(h, h2); } } for (auto it = vi.begin(); it != vi.end(); it++) { ans[get(*it)].flag = true ; ans[get(*it)].people++; } sort(ans, ans+1005 , cmp); for (int i = 0 ; i < 1005 ; i++) { if (ans[i].flag) cnt++; } printf ("%d\n" , cnt); for (int i = 0 ; i < 1005 ; i++) { if (ans[i].flag && i == 0 ) printf ("%d" , ans[i].people); else if (ans[i].flag) printf (" %d" , ans[i].people); } return 0 ; }

 wechat
wechat alipay
alipay/graph.jpg)