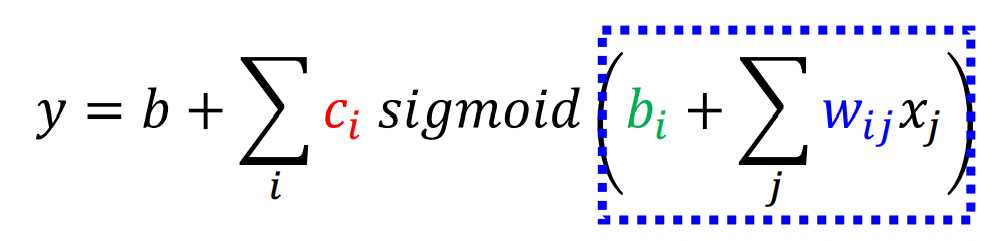论文阅读Knowledge Vault
题目归属及框架

前言
谷歌公司正在打造人类历史上最大的知识库Knowledge Vault
这个被冠以Knowledge Vault之名的知识库无需任何人工干预,就能自动搜集源自互联网的信息并将其整合成单一的事实库,内容涉及世界、人物以及相关对象。这种知识采集机制达到的广度和精度,正在日益成为各种便于机器人和智能手机理解人们对其提问的系统的基础。它有望让“谷歌”超越搜索引擎功能,像“甲骨文”(Oracle)数据库那样回答问题,甚至还能从新的视角来考察人类历史。
这在篇文章中,作者分析了knowledge vault(KV)知识库这一自动化的过程是如何运转的。
概述
当今世界上已经存在了很多成熟的知识库,但要使知识库的规模更大,需要探索一种自动化的方法来构建数据库。因此,作者在本文提出了一种web规模的概率知识融合方法,将从web上抽取的资源与现有的知识库(如freebase)相结合,并使用了监督学习。正因如此,KV的规模以以往的知识库都要来的大。
关键词:知识库;知识抽取;概率方法;机器学习
动机
-
现有的知识库虽然到达了比较大的规模,但仍具有不完整性,例如Freebase中,71%的人没有出生地。
-
直接从web资源上摘录下来的信息,具有较大的噪声,数据无法直接利用,有很多可信度不高。
贡献
- 使用已有知识库里的先验知识,与web上爬取下来的带有噪声的数据相结合。利用已有的三元组,经过知识推理判断新三元组的正确性,先验概率模型的出现解决了抽取过程中出现错误的问题。
- KV的规模比相同的知识库大。
- 对不同的抽取方法及先验概率方法进行了详细的比较。
KV组件
- 抽取器Extractors:负责从web资源抽取知识,每个抽取器会对实体分配一个置信分数,以此表明该三元组的正确率
- 基于图的先验概率模型Graph-based priors:负责基于已有的知识库,来计算每个三元组的先验概率
- 知识融合Knowledge fusion:负责基于抽取器和先验概率模型,计算三元组的正确的概率
s subject,p predictate
o object,G ExPxE的三维矩阵
当G(s,p,o)=1时,表示为正三元组
Pr(G(s, p, o) = 1|·) 计算其正确概率
Local closed world assumption(LCWA)
这是KV知识库的底层假设,所有的抽取和概率计算基于它,内容如下:
O(s,p) as the set of existing object values for a given s and p.
给定一个(s,p,o),如果(s,p,o) ∈ O(s,p),则它是正确的
如果 (s,p,o) !∈ O(s,p)并且 |O(s,p)| > 0,则它是错误的
如果|O(s,p)| = 0,我们就不打标签并把(s,p,o)扔出训练和测试集
抽取器(Extractors)
抽取方法
Text documents(TXT)
- 运行一套标准的NLP工具,做命名实体识别,词类标注,依赖分析和实体链接
- 用远程监督训练关系抽取器。对每一个感兴趣的谓词,从现有知识库提取含有这个谓词的实体对。然后在txt中进行匹配,抽取句子的特征和模式。
为每一个谓词用逻辑回归拟合一个分类器:
输入:含有该谓词的sentences的features和patterns
训练集:根据LCWA进行标注的sentences
HTML trees (DOM)
输入:实体特征向量的词汇化路径
输出:被抽取三元组的得分
HTML tables (TBL)
- 执行了一个命名实体链接
- 用已有的知识库,识别表格中每一列实体的关系。模棱两可的列将被直接的抛弃。
- 被抽取三元组的得分由命名实体链接系统返回
Human Annotated pages(ANO)
为不同的谓词定义了从schema.org(语义库)到FB的手工映射。
被抽取三元组的得分由命名实体链接系统返回
抽取器比较
通过为不同的方法计算AOC曲线,来进行比较
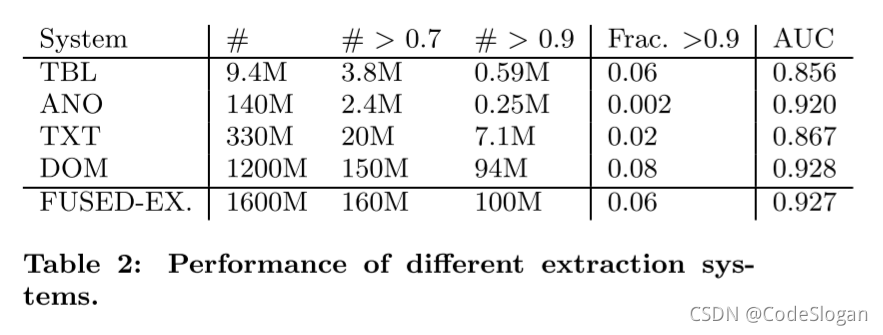
从抽取的数量,以及抽取的三元组的正确度,进行比较后得出,DOM抽取器的表现最好
抽取器结果合并
为每一个三元组建立特征向量
特征向量由两个值组成:
- 抽取这个三元组所用到的源数据的数量的平方根
- 抽取三元组用到的所有源数据抽取器打分的平均分
基于图的先验概念计算(Priors)
Web上抽取的事实可能是不正确的,我们用Freebase上面已经存在的三元组来拟合一个先验模型,这个模型能够计算任何给定的三元组的正确概率,即使之前在Freebase里面不存在。下面给出两种算法:
路径排序算法
Path ranking algorithm (PRA)
在实体集合中,对于每个s,从s开始在图里面随机地walk,如果能够到对应地o,我们就把这个路径记下来,这可以看作是一种规则(rule)。


每一个实体对都会有很多这样的rule,我们拟合一个二分类器来合并这些路径(得到公共路径)。这个时候我们成功地把一个确定的关系(谓词)p转化为了很多这样的路径,然后再训练一个分类器,以这些路径为特征,来推导谓词p。每个谓词p,都训练一个分类器。
Neural network model (MLP)
作者为每一个谓词关联了一个向量,不同于常规方法的是,使用了一个标准的多元感知层来捕获交互信息,计算三元组的概率

其中A向量为L x (3K)的矩阵,3K同时是u,w,v的维度,以此来作为第一层的权重
β为L x 1 的向量,作为第二层的权重。
作者令L=K=60,最后参数的时间复杂度为O(L+LK+KE+KP)
经过实验,MLP和PRA取得了一样的效果。
Extractors + Priors
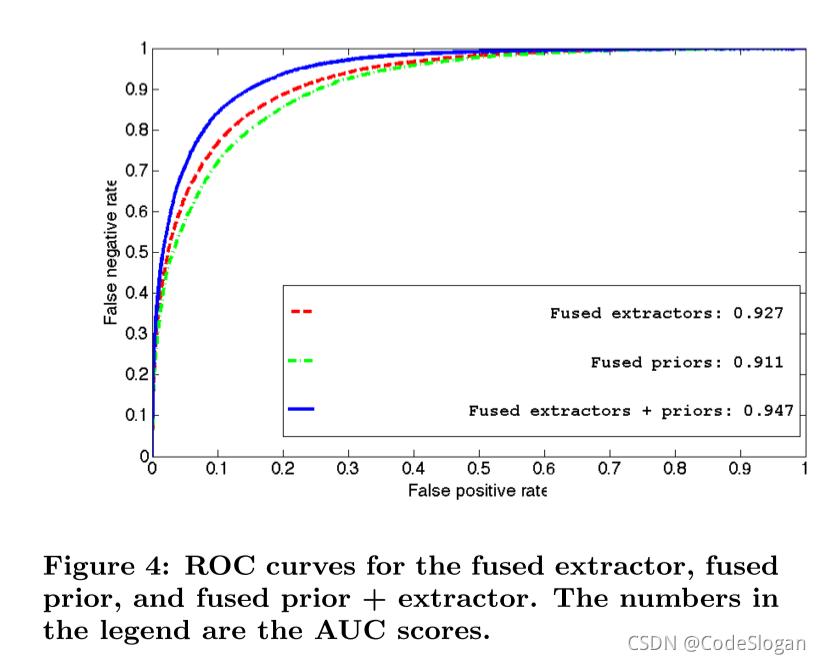
这里的抽取器与先验概率模型合并的方法,与上文的抽取器结果合并方法相同。通过文中Figure 4的图像我们得出,两个模型合并后取得了显著的效果。
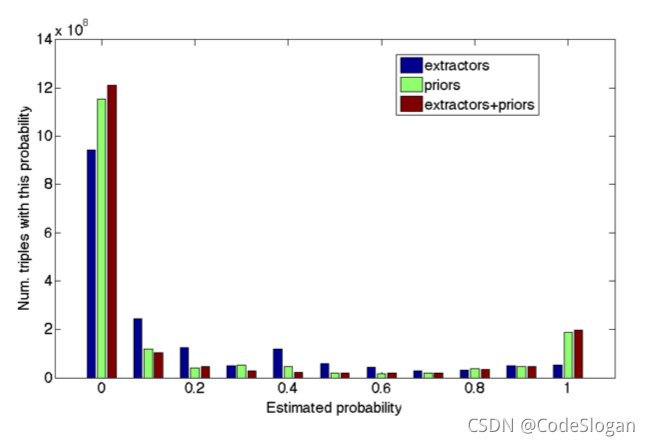
图中的横坐标表示估计的三元组的正确的概率
纵坐标对应其三元组的个数,从图中得出以下结论:
- 不确定的三元组的数量下降
- 提高高可信度事实的数量
思考
关于知识图谱的思考,下面这些问题还未有很好的解决方案,仍在探索中
- 事实之间的互斥性:字面意思说是互斥性,在实际的例子中更准确的表达是事实并不一定是互斥的,也有可能是包含关系。例如,我们可能有一个事实,说奥巴马出生在檀香山,另一个说他出生在夏威夷,这些并不是相互排斥的
- 事实之间的软相关性:我们预计一个人的出生日期比他们孩子的出生日期早15到50年
- 值可以在多个抽象层次上表示:我们可以不同的粒度上表示世界,也就是宏观和微观。这同时也解决了上述提到的事实之间的互斥性
- 事实的时效性:有些事实只是暂时的。例如,谷歌的现任CEO是拉里•佩奇,但从2001年到2011年,CEO是埃里克•施密特。这两个事实都是正确的,但只是在指定的时间间隔内。
- 添加新的实体和关系:添加新的实体所带来的冗余和同义关系
总结
在本文中,作者描述了如何构建一个web规模的概率知识库,称之为知识库。
与以前的工作相比,作者将多个提取源与从现有知识库中(如 FB)获得的先验知识融合在一起。得到的知识库大约是现有自动构造的知识库的38倍。
作者希望在未来,能够继续扩大KV,存储更多关于世界的知识,并利用这个资源来帮助各种下游应用,如问题解答、基于实体的搜索等。
 wechat
wechat alipay
alipay