前言
记录算法竞赛中经过考察的数据结构,其中包括树与图的存储,高级数据结构并查集,Hash表的实现,KMP,栈与队列,以及STL中各容器的使用,需要重点掌握
cin, cout加速代码句
1 2 cin .tie(0 );ios::sync_with_stdio(false );
链表
单链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int head, e[N], ne[N], idx;void init () head = -1 , idx = 0 ; } void add_to_head (int x) e[idx] = x, ne[idx] = head, head = idx++; } void add (int k, int x) e[idx] = x, ne[idx] = ne[k], ne[k] = idx++; } void remove (int k) ne[k] = ne[ne[k]]; }
AcWing826.单链表
双链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int e[N], l[N], r[N], idx;void init () r[0 ] = 1 , l[1 ] = 0 , idx = 2 ; } void add (int k, int x) e[idx] = x; r[idx] = r[k]; l[idx] = k; l[r[k]] = idx; r[k] = idx++; } void remove (int k) r[l[k]] = r[k]; l[r[k]] = l[k]; } void insertL (int x) e[idx] = x; l[idx]=0 ; r[idx]=r[0 ]; r[0 ]=idx; l[r[idx]]=idx; idx++; } void insertR (int x) e[idx] = x; r[idx]=1 ; l[idx]=l[1 ]; r[l[idx]]=idx; l[1 ]=idx++; }
AcWing827.双链表
栈
数组模拟栈
1 2 3 4 5 6 7 8 9 10 11 int stk[N], tt;stk[++tt] = x; tt--; stk[tt]; if (tt > 0 ) { }
单调栈
从当前位置的左边找到一个离它最近且比它小的数
维护一个栈,来实现上述问题
引申:每当倒序寻找一个数时,可以考虑用栈来简化问题,减少时间复杂度
1 2 3 4 5 6 7 8 9 int stk[N], tt;while (n -- ) { int x; scanf ("%d" , &x); while (tt && stk[tt] >= x) tt--; ... stk[++tt] = x; }
队列
普通队列
1 2 3 4 5 6 7 8 9 10 11 12 int q[N], hh, tt = -1 ;q[++tt] = x; hh++; q[hh]; if (hh <= tt) { }
循环队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int q[N], hh = 0 , tt = 0 ;q[tt ++ ] = x; if (tt == N) tt = 0 ;hh ++ ; if (hh == N) hh = 0 ;q[hh]; if (hh != tt) { }
单调队列
维护一个单调队列,队头元素即为最小值
1 2 3 4 5 6 7 8 9 10 11 int hh = 0 , tt = -1 ;for (int i = 0 ; i < n; i ++ ) { if (hh <= tt && i - k + 1 > q[hh]) hh++; while (hh <= tt && a[q[tt]] >= a[i]) tt--; q[++tt] = i; ... }
AcWing154.滑动窗口
KMP
重点为对next数组的理解(当前学的时候就没掌握,终于在y总的带领弄懂了^_^)
表示的是在子串中,p[1, j] = p[i - j + 1, i]
即当前位置往前数的j个,与该串开头的j个相等(相当于一个回退的过程)
作用 :KMP中next数组的出现,使得子串在与主串比较时,不必从头开始比较。在子串往后移动的过程中,(假设成功匹配)必然会出现与原有位置重合的部分,而next数组就是为了记录这一重合部分的长度,避免了o ( n 2 ) o(n^2) o ( n 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for (int i = 2 , j = 0 ; i <= n; i++) { while (j && p[i] != p[j+1 ]) j = ne[j]; if (p[i] == p[j+1 ]) j++; ne[i] = j; } for (int i = 1 , j = 0 ; i <= m; i++) { while (j && s[i] != p[j+1 ]) j = ne[j]; if (s[i] == p[j+1 ]) j++; if (j == n) { printf ("%d " , i-n); j = ne[j]; } }
Trie
维护一个根结点为0的树,来处理字符串集合 (精确到每一个字符),提供字符串的插入和查询操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int son[N][26 ], cnt[N], idx;void insert (char *str) int p = 0 ; for (int i = 0 ; str[i]; i++) { int u = str[i] - 'a' ; if (!son[p][u]) son[p][u] = ++idx; p = son[p][u]; } cnt[p]++; } int query (char *str) int p = 0 ; for (int i = 0 ; str[i]; i++) { int u = str[i] - 'a' ; if (!son[p][u]) return 0 ; p = son[p][u]; } return cnt[p]; }
并查集
并:将两个集合合并
查:询问两个元素是否在同一个集合当中
基本原理:每个集合用一棵树表示,树根就代表集合的编号。对于查操作,遍历查找该点的父结点,判断父结点是否相同即可。对于并,相当于两棵树的合并。
朴素并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int p[N]; int find (int x) if (p[x] != x) p[x] = find(p[x]); return p[x]; } for (int i = 1 ; i <= n; i ++ ) p[i] = i;p[find(a)] = find(b);
维护集合大小的并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int p[N], size[N]; int find (int x) if (p[x] != x) p[x] = find(p[x]); return p[x]; } for (int i = 1 ; i <= n; i ++ ) { p[i] = i; size[i] = 1 ; } if (find(a) == find(b)) continue ; size[find(b)] += size[find(a)]; p[find(a)] = find(b); size[find(x)];
堆(Heap)
通常是一个可以被看做一棵完全二叉树 (当树的深度为h时,前h-1层的结点数都达到最大个数,第h层的结点均集中在最左边)的数组对象
将根结点最大的堆叫做最大堆 或大根堆 ,根结点最小的堆叫做最小堆 或小根堆 。
手写堆支持以下操作:
插入一个数
求集合当中的最小值
删除最小值
删除任意一个元素
修改任意一个元素
1 2 3 4 5 6 7 heap[++size] = x; up(size); heap[1 ]; heap[1 ] = heap[size]; size--; down(1 ); heap[k] = heap[size]; size--; down(k); up(k); heap[k] = x; down(k); up(k);
堆排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int h[N], size;for (int i = n / 2 ; i; i--) down(i);void down (int u) int t = u; if (2 * u <= size && h[2 *u] < h[t]) t = 2 * u; if (2 * u + 1 <= size && h[2 *u+1 ] < h[t]) t = 2 * u + 1 ; if (t != u) { swap(h[u], h[t]); down(t); } } void up (int u) while (u / 2 && h[u / 2 ] > h[u]) { swap(h[u / 2 ], h[u]); u /= 2 ; } }
AcWing838.堆排序
带映射堆
ph[]存储的是第x个插入的元素是……(对应到堆的下标)
hp[]存储的是堆中的某个数是第几个插入的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int h[N], ph[N], hp[N], size;for (int i = n / 2 ;i ; i--) down(i);void heap_swap (int a, int b) swap(ph[hp[a]], ph[hp[b]]); swap(hp[a], hp[b]); swap(h[a], h[b]); } void down (int u) int t = u; if (u * 2 <= size && h[u * 2 ] < h[t]) t = u * 2 ; if (u * 2 + 1 <= size && h[u * 2 + 1 ] < h[t]) t = u * 2 + 1 ; if (t != u) { heap_swap(t, u); down(t); } } void up (int u) while (u / 2 && h[u / 2 ] > h[u]) { heap_swap(u/2 , u); u /= 2 ; } }
模拟堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <iostream> #include <string.h> using namespace std ;const int N = 1e5 + 10 ;int h[N], ph[N], hp[N], sz;void heap_swap (int a, int b) swap(ph[hp[a]],ph[hp[b]]); swap(hp[a], hp[b]); swap(h[a], h[b]); } void down (int u) int t = u; if (u*2 <= sz && h[u*2 ] < h[t]) t = 2 *u; if (u*2 +1 <= sz && h[u*2 +1 ] < h[t]) t = 2 *u+1 ; if (t != u) { heap_swap(t, u); down(t); } } void up (int u) while (u/2 && h[u/2 ] > h[u]) { heap_swap(u/2 , u); u /= 2 ; } } int main () int n, m = 0 ; scanf ("%d" , &n); while (n -- ) { char op[10 ]; int k, x; scanf ("%s" , op); if (!strcmp (op, "I" )) { scanf ("%d" , &x); sz++; m++; h[sz] = x; ph[m] = sz; hp[sz] = m; up(sz); } else if (!strcmp (op, "PM" )) { printf ("%d\n" , h[1 ]); } else if (!strcmp (op, "DM" )) { heap_swap(1 , sz); sz--; down(1 ); } else if (!strcmp (op, "D" )) { scanf ("%d" , &k); k = ph[k]; heap_swap(k, sz); sz--; down(k), up(k); } else if (!strcmp (op, "C" )) { scanf ("%d%d" , &k, &x); k = ph[k]; h[k] = x; down(k), up(k); } } return 0 ; }
Hash表(散列表)
散列表,又叫哈希表(Hash Table),是能够通过给定的关键字的值直接访问到具体对应的值的一个数据结构。也就是说,把关键字映射到一个表中的位置来直接访问记录,以加快访问速度。
典型的以空间换时间 的存储结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 for (int i = 100000 ;;i++) { bool flag = true ; for (int j = 2 ; j*j < i; j++) { if (i % j == 0 ) { flag = false ; break ; } } if (flag) { cout << i << endl ; break ; } }
冲突处理方式
由于Hash表是将大规模的数映射到一个相对较小的数组空间上,必然会出现两个值的键相同的情况,这被称为哈希冲突 ,也叫哈希碰撞
开放寻址法
若冲突,则直接往后一位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 const int N = 200003 , null = 0x3f3f3f3f ;int h[N];memset (h, 0x3f , sizeof h);int find (int x) int k = (x % N + N) % N; while (h[k] != null && h[k] != x) { k++; if (k == N) k = 0 ; } return k; }
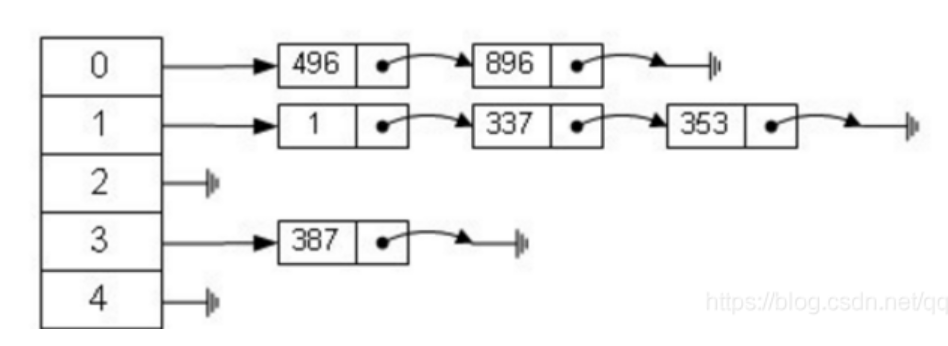
拉链法
以单链表 的形式来处理冲突
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int h[N], e[N], ne[N], idx;memset (h, -1 , sizeof h); void insert (int x) int k = (x % N + N) % N; e[idx] = x, ne[idx] = h[k], h[k] = idx++; } bool find (int x) int k = (x % N + N) % N; for (int i = h[k]; i != -1 ; i = ne[i]) if (e[i] == x) return true ; return false ; }
字符串哈希
重点掌握,判等字符串的一把利剑!!!
将字符串看成P进制的数
转换为十进制 mod Q
1)经验值 :P = 131 o r 13331 P=131or13331 P = 131 or 13331 Q = 2 64 Q=2^{64} Q = 2 64
2)计算任一前缀的字符串哈希:
h ( i ) = h ( i − 1 ) ∗ P + s t r ( i ) h(i) = h(i - 1) * P + str(i) h ( i ) = h ( i − 1 ) ∗ P + s t r ( i )
3)计算出任一子串(L->R)的哈希值:
h [ R ] − h [ L − 1 ] ∗ P R − L + 1 h[R] - h[L-1]*P^{R-L+1} h [ R ] − h [ L − 1 ] ∗ P R − L + 1
注意,子串哈希值的大小只和它的内容有关,和在原字符串中的位置无关
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 typedef unsigned long long ULL; const int P = 131 or 13331 ;char str[N];ULL h[N], p[N]; p[0 ] = 1 ; for (int i = 1 ; i <= n; i ++ ) { p[i] = p[i - 1 ] * P; h[i] = h[i - 1 ] * P + str[i]; } ull get (int l, int r) { return h[r] - h[l - 1 ] * p[r - l + 1 ]; }
参考资料
AcWing算法基础课


 wechat
wechat alipay
alipay
/graph.jpg)