constint N = 10; int n; char str[N][N]; // 分别记录列、对角线、反对角线 bool col[N], dg[N], udg[N];
// u为行数 voiddfs(int u){ if (u == n) { for (int i = 0; i < n; i ++ ) puts(str[i]); puts(""); return; } for (int i = 0; i < n; i ++ ) { // y = x + b -> b = y - x // y = -x + b -> b = y + x if (!col[i] && !dg[i-u+n] && !udg[i+u]) { str[u][i] = 'Q'; col[i] = true, dg[i-u+n] = true, udg[i+u] = true; //标记 dfs(u+1); col[i] = false, dg[i-u+n] = false, udg[i+u] = false; //还原 str[u][i] = '.'; } } }
intmain() { scanf("%d", &n); for (int i = 0; i < n; i ++ ) for (int j = 0; j < n; j ++ ) str[i][j] = '.'; dfs(0); return0; }
// BFS #include<iostream> #include<cstring> #include<algorithm> #define x first #define y second
usingnamespacestd;
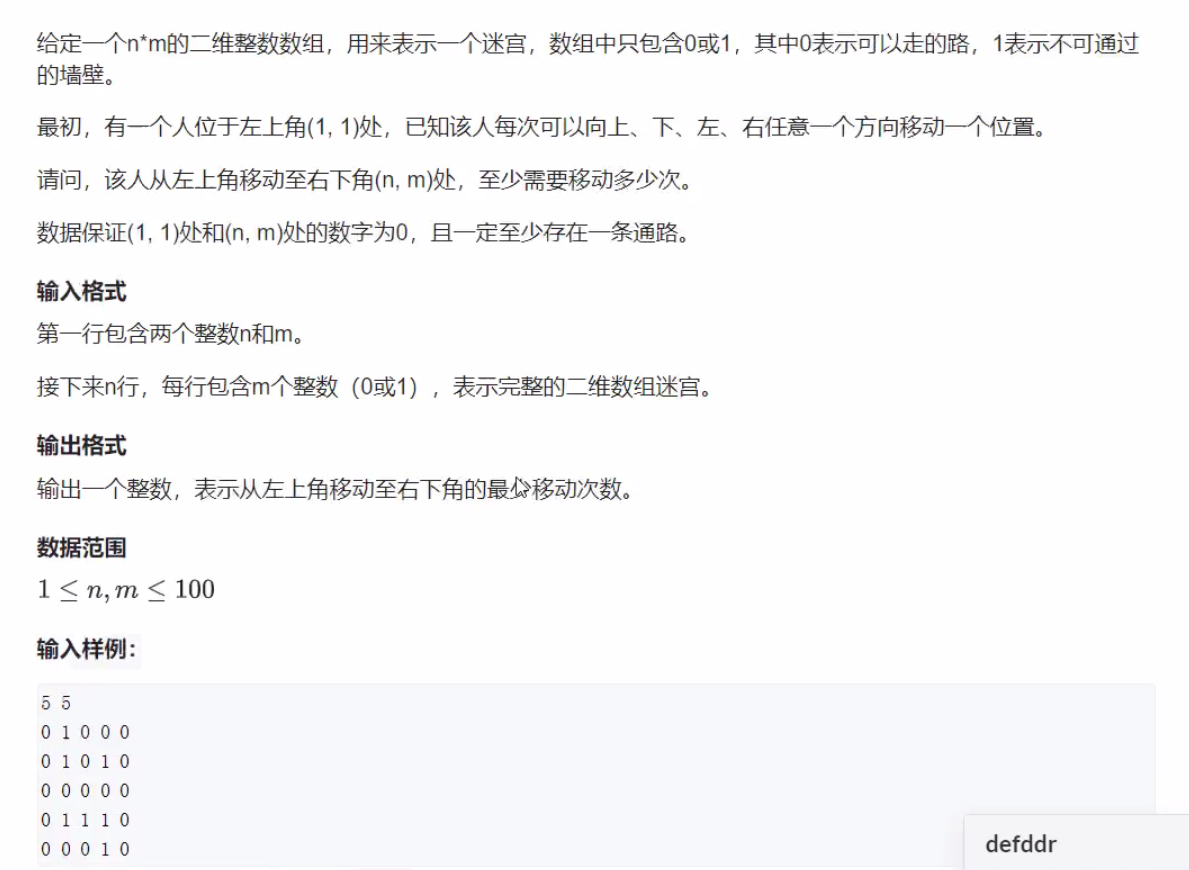
constint N = 110; typedefpair<int, int> PII; int n, m; int g[N][N]; // 记录图 int d[N][N]; // 记录距离的同时标记此点是否已访问 PII q[N*N], path[N][N]; // 模拟队列,记录过程路径 int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
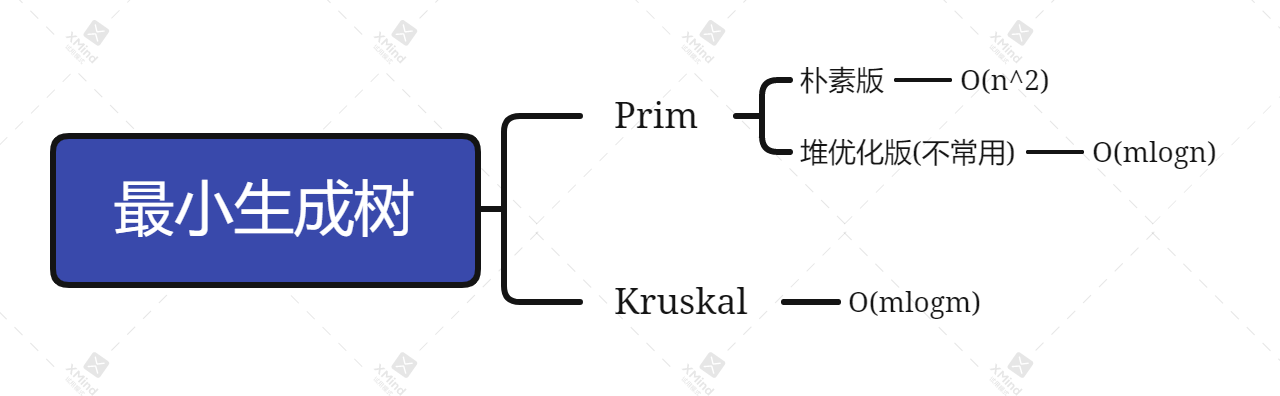
intdfs(){ int hh = 0, tt = -1; q[++tt] = {1, 1}; memset(d, -1, sizeof d); // 初始化为-1 d[1][1] = 0; while (hh <= tt) { auto t = q[hh++]; for (int i = 0; i < 4; i++) { int x = t.x + dx[i], y = t.y + dy[i]; if (x >= 1 && x <= n && y >= 1 && y <= m && g[x][y] == 0 && d[x][y] == -1) { d[x][y] = d[t.x][t.y] + 1; // *DP记录下每一层的距离 path[x][y] = t; // *记录下当前点的下一个点 q[++tt] = {x, y}; } } } return d[n][m]; }
intmain(){ scanf("%d%d", &n, &m); for (int i = 1; i <= n; i ++ ) for (int j = 1; j <= m; j++) scanf("%d", &g[i][j]); cout << dfs() << endl; // 反向遍历,得到起点到终点的路径 int a = n, b = m; while (a >= 1 || b >= 1) { cout << a << ' ' << b << endl; auto t = path[a][b]; a = t.first, b = t.second; } return0; }
#include<iostream> #include<cstring> #include<algorithm> #define x first #define y second
usingnamespacestd;
constint N = 110;
int n, m; int g[N][N]; // 记录图
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1}; int minPath = 1e9; bool st[N][N];
intdfs(int x, int y, int step){ if (x == n && y == m) { minPath = min(minPath, step); return minPath; } for (int i = 0; i < 4; i++) { int a = x + dx[i], b = y + dy[i]; if (a >= 1 && a <= n && b >= 1 && b <= m && g[a][b] == 0 && !st[a][b]) { st[x][y] = true; // 标记已访问 dfs(a, b, step + 1); st[x][y] = false; // 恢复现场 } } }
intmain(){ scanf("%d%d", &n, &m); for (int i = 1; i <= n; i ++ ) for (int j = 1; j <= m; j++) scanf("%d", &g[i][j]); dfs(1, 1, 0); cout << minPath << endl; return0; }
constint N = 1e5 + 10, M = 2*N; int n; bool st[N]; int h[N], e[M], ne[M], idx; int ans = N;
voidadd(int a, int b){ e[idx] = b, ne[idx] = h[a], h[a] = idx++; }
// 返回以u为根结点子树的结点个数 intdfs(int u){ st[u] = true; // sum:存储 以u为根的树 的节点数,包括u // res:存储 删掉某个节点之后,最大的连通子图节点数 int sum = 1, res = 0; for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (!st[j]) { int s = dfs(j); // 返回以j为根结点的子树中的结点数,包括其本身 res = max(res, s); // 比较u结点的每个子树大小,取最大 sum += s; //计算u结点以下所有子树结点之和,包括u本身 } } res = max(res, n - sum); // 最大的子树与u结点以上部分作比取最大值 ans = min(ans, res); // 比较得出最大值中的最小值,即为重心 return sum; }
intmain(){ scanf("%d", &n); memset(h, -1, sizeof h); for(int i = 0; i < n-1; i++) { int a, b; scanf("%d%d", &a, &b); add(a, b), add(b, a); } dfs(1); cout << ans << endl; return0; }
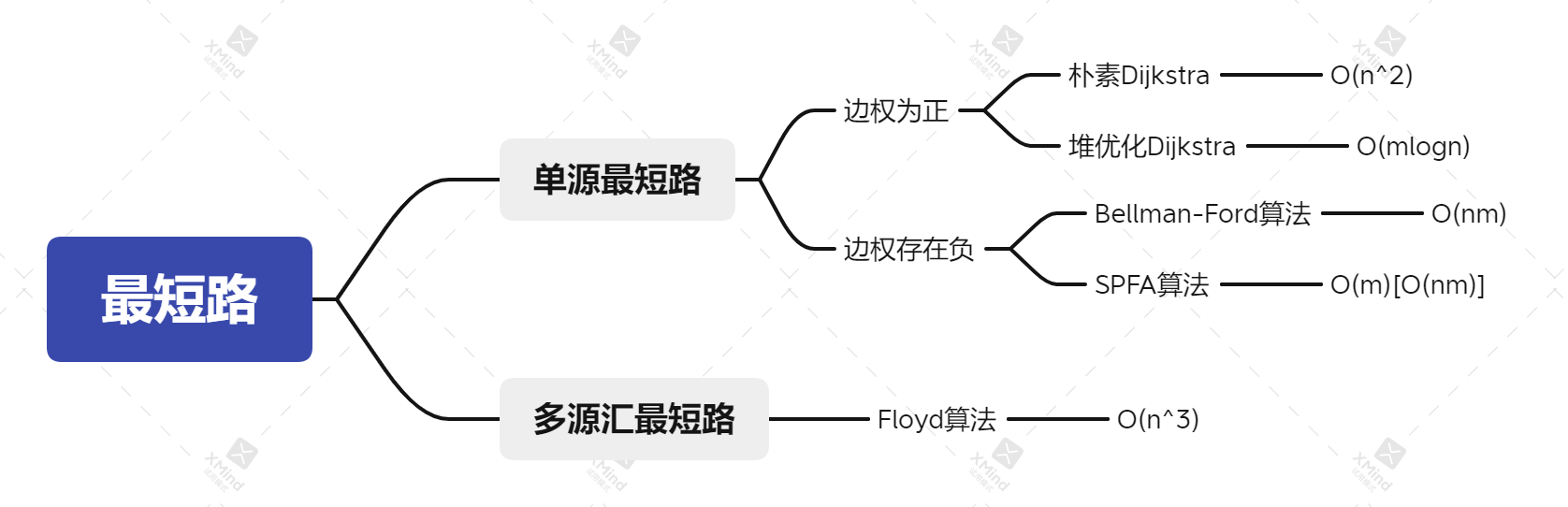
intkruskal(){ // 1. 按权重排序 sort(edges, edges + m); // 初始化并查集 for (int i = 1; i <= n; i++) p[i] = i; int res = 0, cnt = 0; // 2. 枚举每条边 for(int i = 0; i < m; i++) { int a = edges[i].a, b = edges[i].b, w = edges[i].w; a = find(a), b = find(b); if (a != b) { // 如果ab不连通 res += w; cnt++; p[a] = b; // 使得ab连通,从而避免成环 } } // 如果边数与顶点-1不相等,证明图无法连通 if (cnt < n - 1) return INF; elsereturn res; }
booldfs(int u, int c){ color[u] = c; for(int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (!color[j]) { if (!dfs(j, 3 - c)) returnfalse; // c为1的时候,转换为2。反之为1 } elseif (color[j] == c) returnfalse; // 如果染色重复(11,22),则不是二分图 } returntrue; }




 wechat
wechat alipay
alipay
/graph.jpg)