InstructGPT数据标注问题
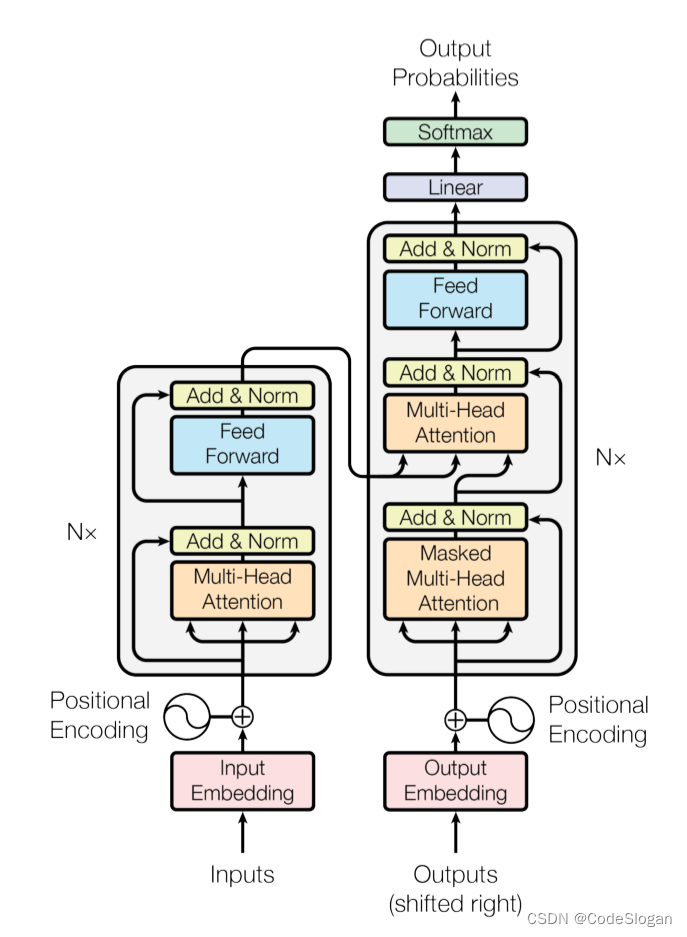
1 背景介绍
ChatGPT的训练过程与InstructGPT相近,大致分为三步:
- SFT:收集描述型数据,对GPT3.5有监督微调
- RM:收集对比型数据,训练一个奖励型模型(RM)
- PPO:使用PPO算法,用RM继续微调GPT3.5
由上述可见,任何一个训练过程,首当其冲的是获取到每个任务阶段所需要的标注型数据,因此本文将对ChatGPT可能使用到的数据及其标注方法进行介绍。
2 标记员筛选
由于在ChatGPT微调的过程中,对数据极为敏感,人们所希望的语言对话模型所生成的回答应该是真实、无害、有帮助的,并且在模型评估时,真实、无害是基本要素。在这样的需求下,openAI在挑选标记员时进行了一系列的筛选测试,从而保证结果的可靠性。
2.1 标记员筛选标准
- 对敏感言论的看法。敏感言论指的是能够引起人的强烈负面情绪的言论,openai要求标记者对其看法应尽量一致;
- 答案排名能力。要求标记员与研究人员,就模型给出的问题回答排序应一致;
- 识别不同领域的敏感内容的能力。
3 数据集及其标注
3.1 预训练
由于无论是ChatGPT所采用的GPT3.5,还是InstructGPT所采用的GPT3,都是事先训练好的预训练模型进行微调,所以无需太多关注预训练阶段所使用的数据。
在预训练阶段,模型采用无监督学习方式,所采用数据集来自大规模文本数据,如网页、电子书、新闻文章、博客等,无需进行标注。训练过程中,模型接受一个输入序列(通常是文本的一部分),通过前面已经生成的部分来预测接下来的一个单词。在训练过程中,模型会根据预测结果和实际标签的差异来更新模型的参数,以使得模型能够更好地预测下一个单词(与GPT训练方式相似)。
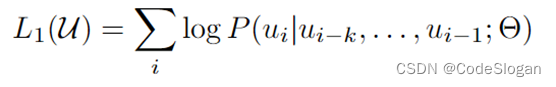
上式描述了预训练阶段模型的似然函数,模型设置了大小为k的窗口,每次用k个单词去预测随后出现的单词,使整体预测概率最大。
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
3.2 微调
在有了预训练模型阶段,我们将用具体的下游任务类型出现的数据,对模型进行微调,从而产生符合预期的效果。在InstructGPT中,训练过程分为了三个阶段为有监督微调(SFT)、奖励模型训练(RM)、基于RM模型使用PPO微调SFT。本节内容将对各阶段出现的数据及标注,各数据集的大小进行介绍
3.2.1 SFT-demonstration data
在微调阶段,模型会使用人类对话数据进一步优化模型,微调阶段属于有监督学习,需要对文本进行标注。对于这个阶段的数据(demonstration data),将会构造或针对给定的问题,由标注工对这些问题进行回答,问题-回答对构成有标签的数据,用于对模型微调。出现的问题形式共有3种:
- plain:直接给出需求问题,如“世界上最大的河?”;
- few-shot:先给出一些问题和回答,再提出新问题。如“给出此条微博的情感分析?”先提供若干条微博信息,并给出其“正面”或者“负面”的标签,再给出一条新的微博内容;
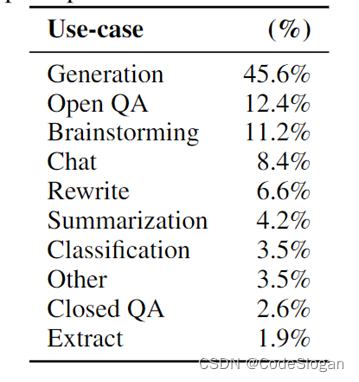
- user-based:根据具体的用户场景设计出的问题,场景类型共10类,如生成类问题,问答,头脑风暴,聊天,重写,总结,分类,抽取等。如头脑风暴场景下的“学习古希腊时应该知道的重点?”,生成类场景下的“写一篇短篇小说,讲述一只棕熊到海滩上,和一只海豹交朋友,然后回家的故事”,对故事进行续写。
3.2.2 RM-comparison data
在RM阶段,针对给定问题,由SFT微调得到的模型先产生对原问题的不同答案,由标注工对答案的正确性进行排序(comparison data),并选择更倾向于模型输出的哪一个答案,如下:
1 | Q:“解释什么是数据结构?” |
以上结果的排序依据,遵从从有帮助性、真实性、无害性三个评估角度出发,其中对绝大多数任务来说,无害性、真实性的权重会远高于有帮助性(训练时则有帮助性权重更高)。但也有特殊情况,如:
- 某一个答案相较于其它提供的帮助非常明显;
- 该输出仅有些许不真实/有害;
- prompt不属于高风险领域(贷款申请、治疗、医疗、法律咨询等),那么将提高“有帮助性”所占的权重。如果出现帮助性相同,但不真实/有害在不同的地方,那么将从用户角度判断哪种可能对用户造成更大的损失,从而将它的排序结果置后。
此外,我们还希望模型具备“ 当输入是一些有害的言论时,希望输出是无害的 ” 的能力。该能力的评价标准将从无害性和连续性出发,这里的连续性指的是输入和输出在逻辑上可以构成一个文本,而不会读起来明显像两个文本的情况。我们将从输出的有害度,输入输出相对有害度,输入输出文本连续性上进行打分,从而依据打分结果获得排序结果。

标记员的在第二个阶段RM标注工作在如下图所示的界面完成。
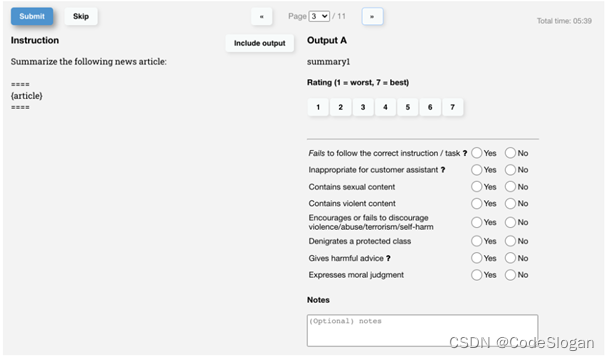

在第一张图中,标注员首先会给出1-7范围内的得分,得分更高的回答质量也更高,并且基于真实性,无害性,有帮助性,给出元数据的标签。而第二张图指的是在上一张图的工作完成以后,对模型的所有输出进行排序。
3.3 数据集大小
在InstructGPT上,雇佣了40人进行标注及API中获得的。
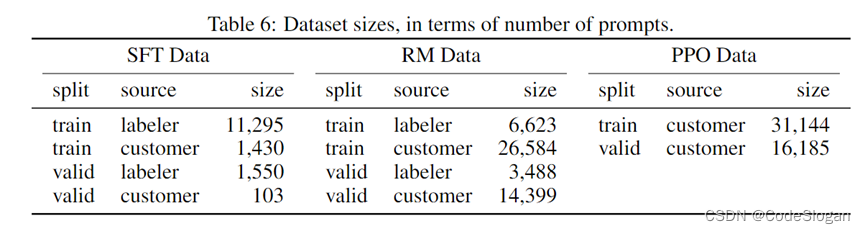
训练集上,SFT标注了13k条数据(API+人工),RM标注了33k(API+人工),PPO标注了31k(API)。
验证集上,SFT任务有1653条,RM有18k条,PPO中有16k条。
4 模型实现
在数据集采集及标注完全后,需要分别训练出两个不同的模型,即SFT和RM。
在SFT阶段,使用采集的问答对数据,对GPT进行有监督微调。
在RM阶段,使用对比数据集,训练RM奖励模型。
RM模型是将SFT去掉softmax层,改成输出为1的线性层,从而在以问答为输入的情况下,输出得到奖励值。
在训练过程中,为了避免过拟合现象的出现,采用成对展示输出结果的方式,然后用户从中选择更好的结果输出。
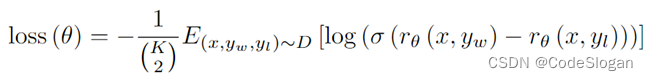
RM所定义的损失函数会最大化两者之间的差值。RM损失函数:x代表prompt,yw代表的是质量较高的回答,yl代表质量较低的,r为奖励模型的输入结果。每轮对prompt的所有回答进行两两比较,这样设计损失函数使得yw(质量较高回答)的得分尽可能高,最大化两个回答之间的差值。
在最后PPO阶段,是利用第二步得到的奖励模型,指导SFT训练,用PPO算法微调SFT。针对给定的问题,由SFT生成回答。问题-回答作为输入,用RM模型得到奖励值,用奖励值使用PPO更新SFT,为一次迭代。由于SFT每轮参数都会发生变化,导致强化学习的环境也改变,所以在损失函数中加入KL散度。
InstructGPT
 wechat
wechat alipay
alipay